突破AI视觉“选择性失明”,哈工大首次实现指令驱动的全景式感知
对于 AI 视觉多模态大模型只关注显著信息这一根本性缺陷,哈工大GiVE实现突破!
当今的多模态大模型(如 BLIP-2、LLaVA)看似可以理解图像,实则存在一个根本性的缺陷:它们像戴着 " 眼罩 " 的观察者,只能关注图片中最显眼的主体,却对用户关心的细节视而不见。
例如,当被问及 " 图中左侧的自行车 " 或 " 背景广告牌上的文字 " 时,模型常因视觉编码器的 " 视野局限 " 而答非所问——要么误判对象位置,要么完全忽略非显著信息。
这种 " 选择性失明 ",严重制约了 AI 在医疗诊断、自动驾驶、智能安防等场景的深度应用。
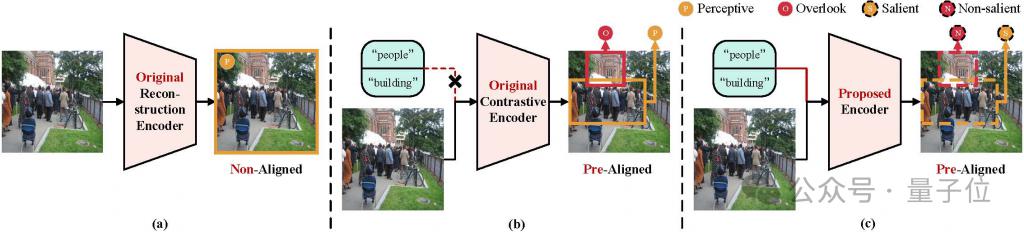
哈工大(深圳)博士生李俊劼最新研究成果《GiVE: Guiding Visual Encoder to Perceive Overlooked Information》,为 AI 视觉装上 " 动态变焦镜头,首次实现 " 指令驱动的全景式感知 "!
与传统模型的 " 固定视角 " 不同,GIVE 能根据用户需求灵活调整注意力焦点:无论是被遮挡的物体(如鞋盒中的鞋子)、分散的同类目标(如人群中的特定行人),还是隐藏在复杂背景中的特定目标(如路边草地),都能精准捕捉并关联语义信息。
实验表明,GiVE 在图像分类、图文检索等任务中,关键指标有显著提升,解决了传统模型 " 见木不见林 " 的痛点。
GiVE 通过引入一系列创新设计,重新定义了视觉编码的效率和精度。
它采用了 AG-Adapter 模块,让模型在解析图像时能灵活关注到各类隐性细节,不仅捕捉到显著特征,还能兼顾那些平时容易忽略的部分。
同时,GiVE 设计了三个专门的 loss,从不同角度优化图像与文本、图像之间以及图像内目标的关联,使得视觉信息的提取更加全面精准。
这一综合方案不仅提升了多模态任务的表现,也为构建更智能、更统一的多模态系统铺平了道路,这不仅是技术的革新,更是 AI 从 " 粗看 " 到 " 细察 " 的认知跃迁——机器的眼睛,终于学会了 " 按需聚焦 "。

GiVE 效果:强大的性能 1、让视觉编码器能够听到文本指令提示
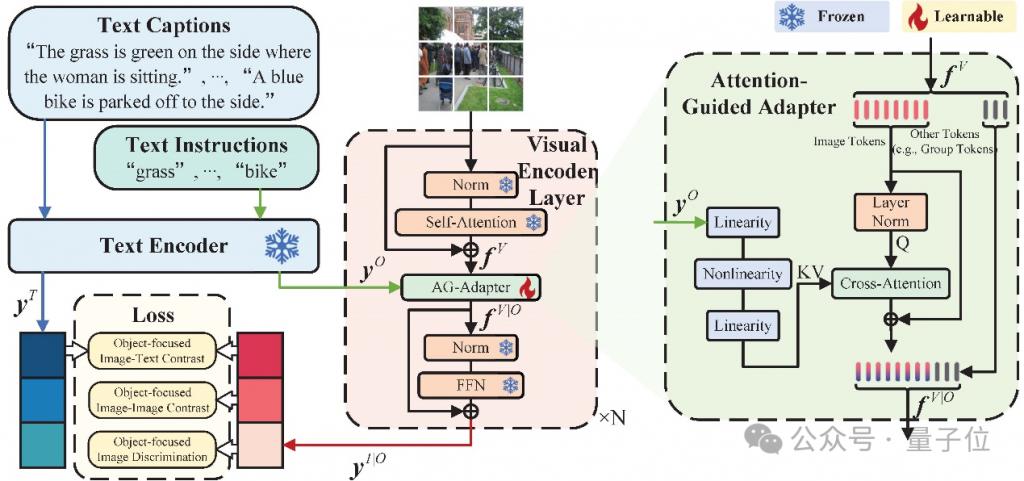
研究团队设计了一个" 注意力引导适配器 "(AG-Adapter)模块,作为插件嵌入现有视觉编码器的层与层之间。
这个 AG-Adapter 可以被理解为在视觉网络中加入了一双 " 耳朵 ",使得视觉编码器在看到图像的同时还能听到文本指令的提示。
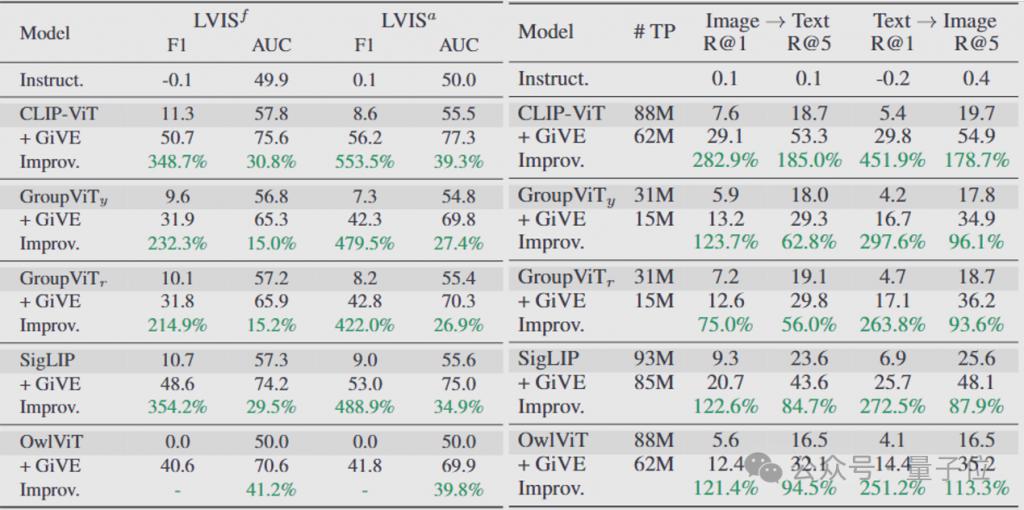
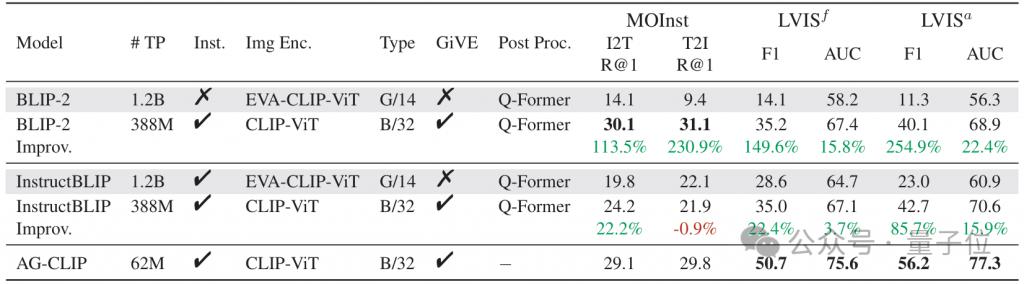
即便是和 InstructBLIP 这样具有指示跟随编码能力的模型比较,GiVE 也可以用 5% 的可训练参数达到更好的性能。
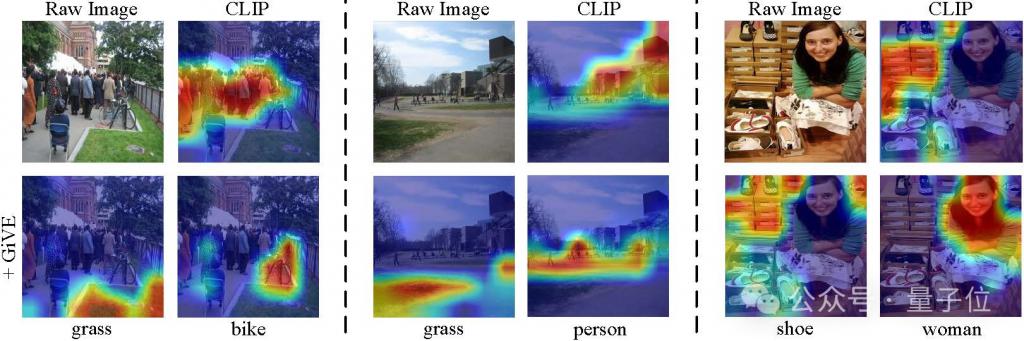
2. 视觉感知的灵活性、有效性和完备性
从可视化注意力可以看出, GiVE 可以让传统视觉编码器灵活聚焦。
3. 在多模态大模型中的应用
正确的聚焦为语言模型提供了充分的上下文信息,有助于生成真实可信的响应。

这里并没有重新训练 LLaVA 模型,而是简单地将 GiVE 应用到其使用的 CLIP 编码器上。
这也体现了 GiVE 的易用性。
GiVE 出手:让视觉模型听懂指令,不放过任何细节
GiVE 旨在突破传统视觉编码器对图像关键信息捕捉的局限,通过全新设计的模块与训练策略,实现更全面、精准的视觉理解。
1、核心组件—— AG-Adapter 模块
灵巧:精确的视觉指导
GiVE 引入了 Attention-Guided Adapter(AG-Adapter)模块,能够根据文本提示动态调整视觉编码器的关注区域。
不同于传统编码器只聚焦于图像中显著的部分,AG-Adapter 使得模型在解析图像时能关注到容易被忽略的细节,从而提高了有效视觉信息的提取效果。
轻便:无缝集成与轻量设计
该模块以相对较低的额外参数成本嵌入到现有视觉编码网络中,保证了高效的推理速度和大规模训练的可扩展性。
同时,它作为一个独立的组件,也方便开发者在不同任务中进行灵活调试和替换。
2、创新训练目标——三大 Loss 函数
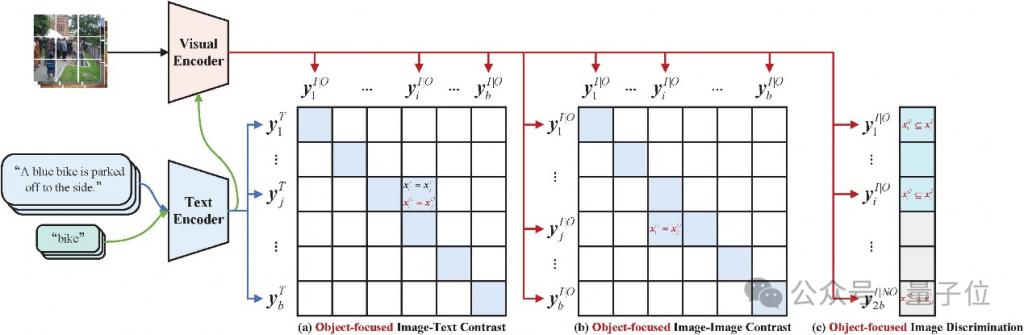
为了使模型能够更好地理解并传递丰富的视觉语义信息,GiVE 设计了三项专门的训练目标:
对象级图像 - 文本对比(Object-focused Image-Text Contrast,OITC)Loss:这一损失函数促使模型在视觉和文本之间建立更紧密的语义联系,通过对比学习有效区分不同对象的特征,使得图像编码结果能够准确反映文本中描述的对象信息。
对象级图像 - 图像对比(Object-focused Image-Image Contrast,OIIC)Loss:OIIC Loss 侧重于提高同一图像内部多个目标之间的关联一致性,确保模型能够在复杂场景中提取到各个目标的共性和细微差别,从而大幅提升对象检索的准确性。
对象级图像辨识(Object-focused Image Discrimination,OID)Loss:通过对图像中目标存在性的二分类判别,OID Loss 帮助模型更全面地捕捉到图像中可能被遗漏的细节,为后续多模态任务提供更加丰富和准确的视觉特征表示。
3、数据基础——多目标指令数据集(MOInst)
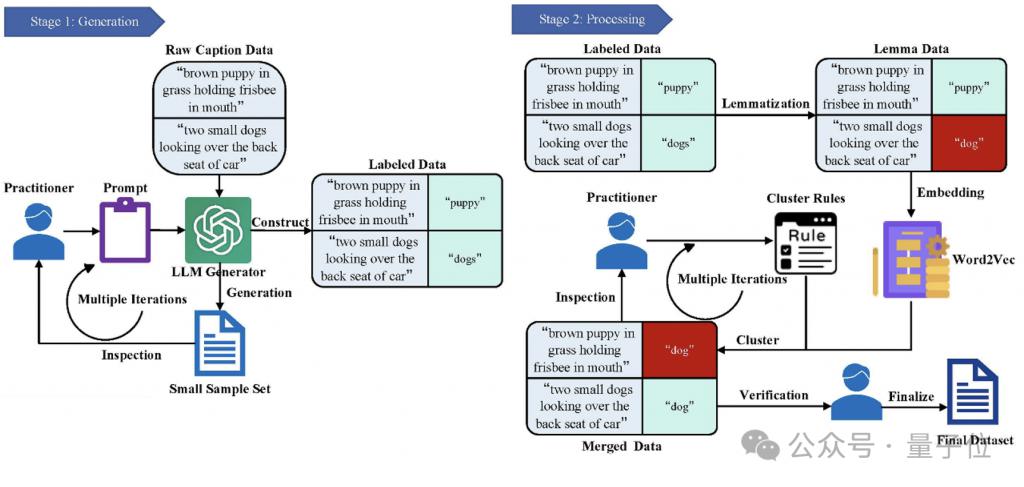
为了更好地训练上述模块和 Loss 函数,GiVE 团队构建了专门的Multi-Object Instruction(MOInst)数据集。
该数据集不仅覆盖了多种对象类别,还为每个图像提供了成对的精细文本指令与对象描述,从数据层面确保模型在训练过程中能够学习到更细粒度的对象关系和语义表达。
组成:数据集包含 8 万张图像、24 万条文本标注及对应的指示对象,覆盖 264 类物体关联场景,为后续研究提供持续助力。

构建:数据集是在现有大语言模型的帮助下,以半自动的方式创建的,辅以少量人工协助。
这种人工审核和自动化工具相结合的方式,确保了数据集的准确性和一致性,并剔除可能存在的噪声和错误标注。
未来方向
GIVE 的愿景,是让 AI 的 " 眼睛 " 不仅 " 看得见 ",更能 " 看得细 "" 看得懂 " ——从静态图像到动态视频的时序解析,从 2D 画面到 3D 点云的空间建模,从单一视觉模态到跨文本、语音、传感器的多维融合。
未来,这项技术将渗透至医疗影像的早期病灶定位、自动驾驶的复杂环境感知、工业质检的微观缺陷识别,甚至机器人对非结构化场景的自主交互。
精细化视觉感知,正成为打通 AI" 感官 " 与 " 认知 " 的关键桥梁,推动通用智能从实验室迈向真实世界的每一个角落。
更多细节欢迎查阅。
代码:
https://github.com/AlephZr/GiVE/tree/main
数据集:
https://huggingface.co/datasets/DF1024/MOInst
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文 / 项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点亮星标
科技前沿进展每日见