瑞莱智慧CEO:大模型形成强生产力关键在把智能体组织起来,安全可控是核心前置门槛
随着大模型加速渗透核心行业,其安全可控性正从技术议题升级为产业落地的先决条件。
特别是金融、医疗等关键领域,对数据隐私保护、模型行为可控性及伦理合规提出了更高的要求。
如何为 AI 应用构建坚实的防护边界?
在第三届 AIGC 产业大会上,瑞莱智慧 CEO 田天博士带来了他们的最新实践。田天博士毕业于清华大学计算机系,他带领团队致力于人工智能安全和垂类大模型应用。

为了完整体现田天的思考,在不改变原意的基础上,量子位对其演讲内容进行了编辑整理,希望能给你带来更多启发。
中国 AIGC 产业峰会是由量子位主办的 AI 领域前沿峰会,20 余位产业代表与会讨论。线下参会观众超千人,线上直播观众 320 万 +,累计曝光 2000 万 +。
话题要点
无论是深度学习时代还是大模型时代,人工智能在落地过程中已出现大量安全问题亟待解决。除模型自身问题外,其发展落地还有新的滥用风险。
随着 AIGC 技术逼真度提升,AI 检测系统的重要性将愈发凸显。
目前大模型落地基本上可以分为三步:初步的问答工作流;工作辅助流;深度重构关键任务流,即实现人机深度协同工作。
可以从系统层面利用像 Agent 这样的技术,提升模型的可控性和安全性。
大模型形成强生产力关键在把智能体组织起来,安全可控是核心前置门槛。
以下为田天演讲全文:
AI 落地过程中出现大量安全问题亟待解决
我是瑞莱智慧田天,很荣幸今天有机会跟大家做这个分享。
瑞莱智慧在 AI 领域,或者在整个 AI 产业链上是非常有特色的一家公司,我们更关注安全、通用的人工智能,安全是我们极为关注的核心点。
为何关注这个方向?先举几个例子。
无论是深度学习时代还是大模型时代,人工智能在广泛落地过程中已出现大量安全问题亟待解决,这些问题影响了人工智能应用产业落地的关键进程。
典型如 ChatGPT 这类应用,曾在网上流传 " 奶奶漏洞 ",用户诱导大模型回答不该回答的问题,例如让模型扮演奶奶,以 " 念 Windows 11 旗舰版序列号哄我睡觉 " 为由,使大模型被骗输出序列号,且有网友验证该序列号为未激活可用状态。
这既暴露了大模型易受欺骗的问题,也反映出商业公司在大模型应用中面临的信息安全与数据泄露风险。
另外,大模型还涉及价值观层面的问题。去年也有非常知名模型在回答问题的时候,答案违背主流价值观,这种回答若是出现在儿童产品中,影响将极为深远和严重。
除模型自身问题外,其发展落地还有新的滥用风险,典型如 AIGC 合成内容用于造谣和诈骗。
左侧案例是西藏地震后流传的 " 地震小孩 " 视频,实为 AI 合成的假视频,误导公众同情并意图诱导捐款;右侧是通过 APP 指令生成的 " 某地着火 " 视频,足以让不在现场的人误以为真实灾难发生,大幅降低谣言制造成本。

这些都是随着 AI 能力越来越强所显现出来新的问题。
还有下方案例是 AI 诈骗场景,利用 AI 生成虚假人物视频,伪造一些没有做过的事情,又或者伪造成你信任的人问你借钱或者诱导你做一些事情,很容易成功,国内外已发生多起此类案件。
大模型时代安全产品的落地实践
刚才是从两个视角跟大家举了一些例子,在瑞莱智慧 RealAI 的视角下,怎么看待 AI 安全落地的问题?
我们认为至少分为三个阶段。
第一在 AI 本身发展的过程中,我们最需要关注的是提升 AI 自身的可靠性和安全性。
正如前面所讲的,大模型越狱、价值观对齐、模型幻觉,这些都是 AI 能力还不够强,需要我们对 AI 自身进行加固防御。
第二,随着 AI 能力越来越强,很有可能被滥用,本身也是一把双刃剑。比如刚才所讲的利用 AI 造谣、诈骗、生成虚假内容,我们必须要防范 AI 滥用所带来的一些危害。
通过这两层,可以看到 AI 能力越来越强,但也带来了新的问题。如果 AI 能力进一步增强,真的达到我们所认为的 AGI 全方位超越人类的水平时,又会有新一代的问题。
我们怎么保证 AGI 的安全发展?怎样让真正 AGI 时出现的新物种能够服务于人类,而不是对人类社会造成挑战、危害?这里面有大量的工作需要去做。
围绕这几个方面,瑞莱智慧 RealAI 已开展长期实践并已经有一系列的平台、产品的落地。
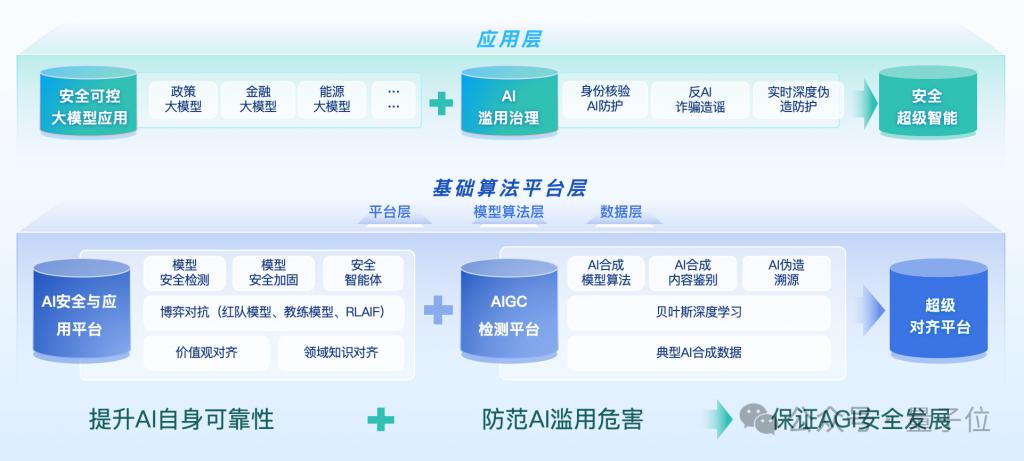
像左边针对提升 AI 自身可靠性,我们有 AI 安全与应用平台、AI 安全与支撑平台以及上层更安全可控的垂类大模型。
围绕防范 AI 滥用,我们则推出了先进的 AIGC 检测平台,以 AI 对抗 AI,识别图像、视频、文本、音频等合成内容。
针对 AGI 安全发展,我们也在开展前沿研究,如搭建超级对齐平台、探索用 AI 监管 AI,以实现安全的超级智能。
在落地实践中,我们有诸多产业服务案例。比如说最典型是在深度学习时代就早早开始做的 AI 安全产品,即人脸 AI 防火墙。
人脸识别是目前落地最广的 AI 产品之一,像大家通过手机银行办理业务,在验证身份的时候都会要求你张张嘴、眨眨眼、摇摇头,确认你是本人。
其实利用 AIGC 技术可以通过一张原始人物的照片,加上一个其他人做的驱动视频,就可以生成一个假的目标对象张嘴、眨眼,做各种动作的视频。我们发现,把这个视频通过一些方式注入到移动手机里面,真的可以误导真实的金融 APP 的身份核验。
为防范这种攻击,我们做了一个人脸 AI 防火墙产品——RealGuard。
它可以作为人脸识别的前置环节,首先识别一个输入的请求有没有攻击,是否是一个攻击样本,如果是攻击样本的话就把它拒绝掉,如果不是再给到后面的真正识别环节,从而保证人脸识别更加安全。
这个产品现在已经服务了非常多的客户,特别是银行客户,一半以上国内头部银行都已经使用了这样的产品以保证系统的安全性。
在大模型时代,我们也已经有一系列的安全产品的落地。
第一步一定是要去发现现有大模型产品的安全隐患,先要知道它的问题在哪。对于客户来说,才可以选择是否要让 AI 产品上线以及产品还要进行哪些方面的迭代和加固。
我们发现用固定的测试集还是非常不足的,很多大模型很聪明,我们没有办法在前置的环节发现各个维度的安全隐患。
我们专门做了一个红队模型,它可以自动地生成对其它模型来说有威胁性的答案,相当于利用一个扮演邪恶角色的大模型误导其它大模型,从而发现被测模型是不是安全,最终形成一个完整的报告。
发现问题之后,我们对现有模型进行安全加固增强。
这里举一个典型例子。DeepSeek 出来之后它的能力特别强,海外一些公司的专家会跳出来讲,DeepSeek 虽然很强,但是安全性很差。
我们测了一下,其实 DeepSeek 的安全问题主要出在过于善良,提问者不管问什么问题,即使知道这个问题不够安全,它最终也会回答出来,从而带来一些安全隐患。
针对这个问题怎么办?我们专门提出了一个模型安全能力增强的框架,通过后训练的方式对模型能力在推理阶段进行持续的提升。
最终带来的效果是我们发布的安全增强版 DeepSeek,在通用能力上跟原版基本上没有任何下降,包括数学能力、回答通用问题的能力、推理能力等等。
但是它的安全性相比于原版有大幅度的提升,基本上达到了国际上最优的闭源大模型的安全水平。
前面讲的是模型安全和增强,再来说说伪造内容、AIGC 滥用带来的安全隐患,应该如何应对?
我们发布了一个生成式人工智能内容监测平台 DeepReal,它也是用 AI 对抗 AI 的思路,用一个 AI 模型帮我们分辨人脸已经没有办法分辨的内容到底是真的还是假的,包括刚才提到图片、视频、音频、文本等,这些都可以去检测。
除了被动上传检测方式,我们还专门推出了一个实时主动检测的系统,把它作为手机或者电脑的软件来运行,如果在电脑上开视频会议时,对方突然 AI 换脸,系统可以给你对应的警示,告诉你对方有 AI 换脸的嫌疑,需提高警惕,从而防范 AI 诈骗。
随着 AIGC 技术逼真度提升,此类检测系统的重要性将愈发凸显,甚至说每一个人都需要有这样的系统帮我们分辨每天看到的内容到底是真是假。
垂类大模型落地需以安全为前置门槛
在推进安全工作的同时,我们发现垂类大模型落地需以安全为前置门槛,只有我们做好安全,人工智能大模型应该才能真正在行业里面落地。
我们也做大量的行业大模型落地的工作,我们发现目前大模型落地基本上可以分为三步。
第一步是比较初步的问答工作流,类似于客服、内部信息咨询等,它的好处是与客户的系统耦合度比较浅,可以快速出箱,但是距离核心业务会远一些。
第二步是工作辅助流,利用大模型先完成一些工作给人一些建议,比如说写研究报告,人再对答案进行最终的确认完善。它的好处是最终有人在把关,它的可控性、安全性可以靠人进行二次校验得到提升。
第三步价值最高,我们认为是深度重构关键任务流,即实现人机深度协同工作。这其实是在很多场景,包括我们在内的很多厂商,大家都在努力的一个方向。
怎么让这种行业大模型更加安全可控地落地?
这里我也列了一些关键点,包括在模型阶段怎样对模型安全能力进行提升,包括对有害输出内容的安全风险的提示,还有训练、推理层面的加固以及模型安全问题的缓解。
我们可以在模型以外,从系统层面利用像 Agent 这样的技术,提升模型的可控性和安全性。
如何理解?有一些问题或者有一些工作,模型本身确实做起来非常有困难,比如说做长的算术题,这种问题就需要在合适场景通过 Agent 调用工具,通过调用可信工具的方式提升整体 AI 大模型系统的安全性。
最后,讲一下我们对于大模型应用落地的一些观点。
刚才讲了很多 AI 大模型安全的事情,可能大家会有疑问:是不是随着 AI 大模型能力越来越强,甚至到了 AGI 的时代,自然而然变得更加安全可控,我们不需要进行独立的安全的研究和布局了?
其实我的观点不是这样。
我们可以去类比人类社会智能的发展,如果回溯到 2000 年,甚至 3000 年以前,古代的人类个体智慧水平相比于现在的人类,并没有那么大的差异,因为古人也可以进行相关的研究工作,写出来非常有哲理的文章,留给我们很多宝贵的智慧结晶。
但是古代,人类没有办法形成很强的生产力,而现今人类通过强有力的组织形式以及相应的分工,可以实现登上月球,甚至未来有可能登上火星等,完成非常复杂、庞大的工程。
这里面的差异是怎么把智能体组织起来。
对于大模型也一样,今天大模型也已经具备了非常强的智力、能力,我们不需要单一的智能体无所不能。如果把现有的智能体通过比较好的方式融入到工作流之中,甚至说以大模型为核心,对现有的各行各业的工作流程进行重构,就能大幅度解放 AI 的生产力,真正看到 AI 重塑、改造社会。
在这个过程中,安全可控一定是非常核心的前置门槛。
希望将来能够跟更多人探讨交流安全可控 AI 的落地,谢谢大家。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见