视频推理R1时刻,7B模型反超GPT-4o!港中文清华推出首个Video-R1

论文链接:https://arxiv.org/abs/2503.21776
项目地址:https://github.com/tulerfeng/Video-R1
知名博主AK也连发2条推特,推荐这篇论文:
所以,视频大模型「不聪明」,真不是没潜力,而是没人教对方法。
一套奖励机制,把视频推理训会了
研究团队整了个狠招:奖励机制绑定时间理解。
研究人员把旧版GRPO算法升级成了更懂时序的T-GRPO,直接把「考虑时序」这事写进了模型的奖励逻辑里。
方法简单粗暴又高效——模型每次会收到两组输入:一组视频帧随机乱序,一组顺序。只有当它在「顺序」输入上答对题的比例更高,才会获得奖励。
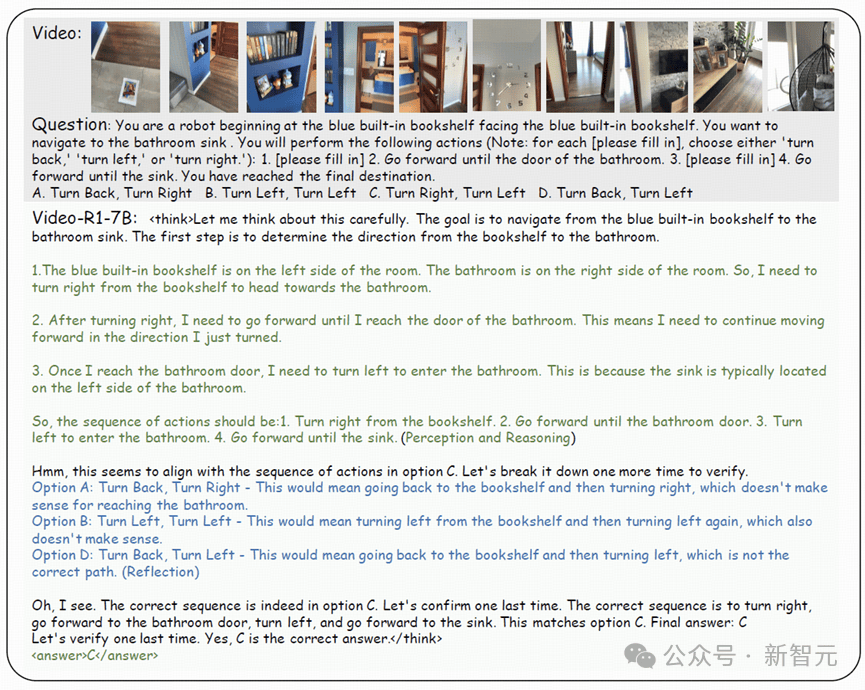
这个机制在「教」模型:别光看图,推理得讲前因后果。哪怕只看了一帧猜对了题,也拿不到分。
在这种严格打分机制下,模型终于明白——视频不是PPT翻页,而是一个个逻辑线索串起来的故事。
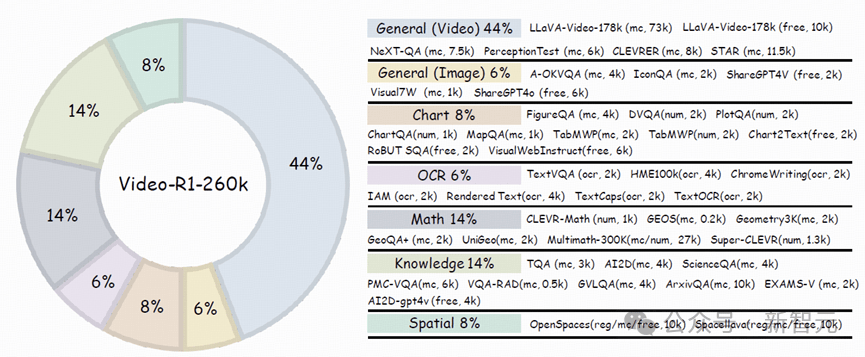
靠混合数据打通任督二脉
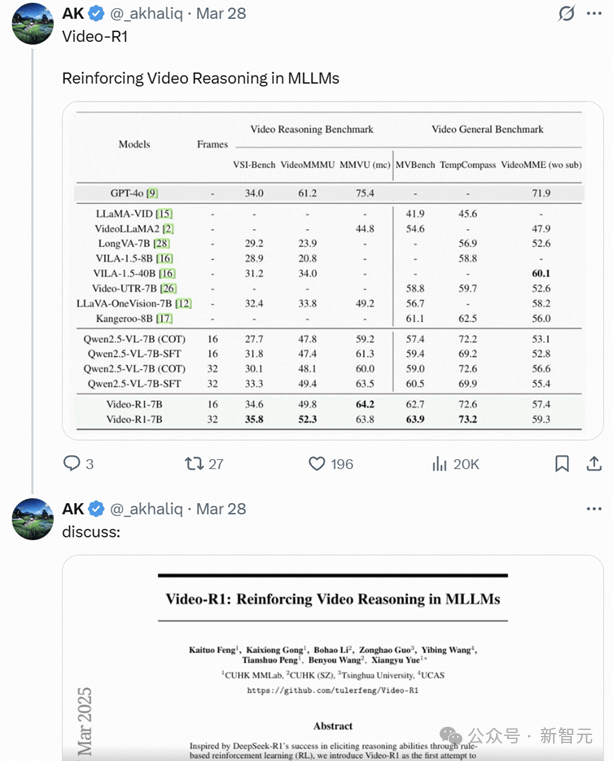
在多个视频推理测试基准上,这个Video-R1-7B模型几乎场场领先,尤其在李飞飞提出的VSI-Bench这一权威评测中,它拿下了35.8%的准确率,超越了闭源顶尖大模型GPT-4o。
不仅如此,RL和传统SFT之间的差距也被拉开了。比如同样是7B体量的Qwen2.5-VL-SFT,在测试中表现不佳。反观Video-R1,则在几乎所有场景中都稳定输出,泛化能力一骑绝尘。
还有一个非常关键的发现:帧数越多,推理越准。当模型输入的视频帧数从16增加到32,再到64,测试表现都跟着上台阶。这说明,对时间线的理解力,正是视频推理模型的决胜点——谁能处理更长的视频,谁就更有未来。
团队还做了一组消融实验,直接「抽掉」图像数据训练、再试试砍掉时间建模模块,结果都一样——模型性能明显下滑。这直接验证了一件事:Video-R1的每一块设计都打在了点子上。

不仅如此,从训练动态中也能看出门道。随着强化学习的推进,模型获得的准确率奖励和时间奖励在持续上升,说明它不仅越来越会答题,还越来越懂得「时间逻辑」这回事。
有意思的是,模型在训练早期输出的回答变短了——这是在主动抛弃之前SFT里学到的次优推理模式;但随着训练推进,输出逐渐恢复并稳定,形成了一套更高效、更具逻辑的表达路径。