清晨重磅!阿里发布并开源Qwen3,无缝集成思考模式、多语言、便于Agent调用
阿里巴巴周一发布并开源通义千问 3.0(Qwen3)系列模型,并称其在数学和编程等多个方面均可与 DeepSeek 的性能相媲美。与其他主流模型相比,Qwen3 还显著降低了部署成本。阿里表示,Qwen3 无缝集成两种思考模式,支持 119 种语言,便于 Agent 调用。
性能媲美 DeepSeek R1、OpenAI o1,全部开源
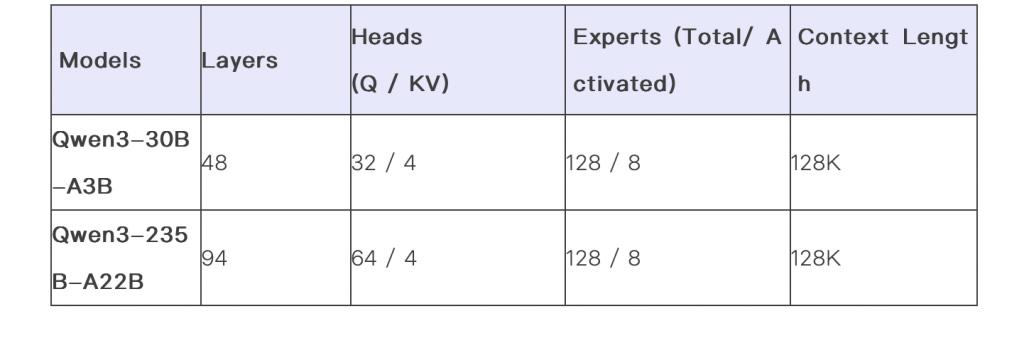
Qwen3 系列包括两个专家混合 ( MoE ) 模型和另外六个模型。阿里巴巴表示,最新发型的旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力。
此外,被称为 " 专家混合 "(MoE,Mixture-of-Experts)模型的 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。这类系统模拟人类解决问题的思维方式,将任务划分为更小的数据集,类似于让一组各有所长的专家分别负责不同部分,从而提升整体效率。
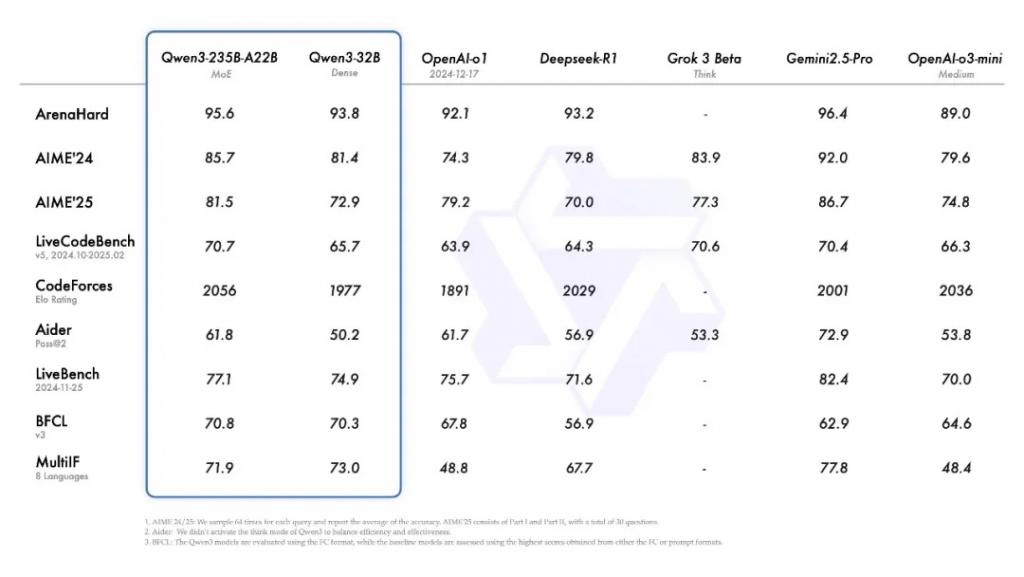
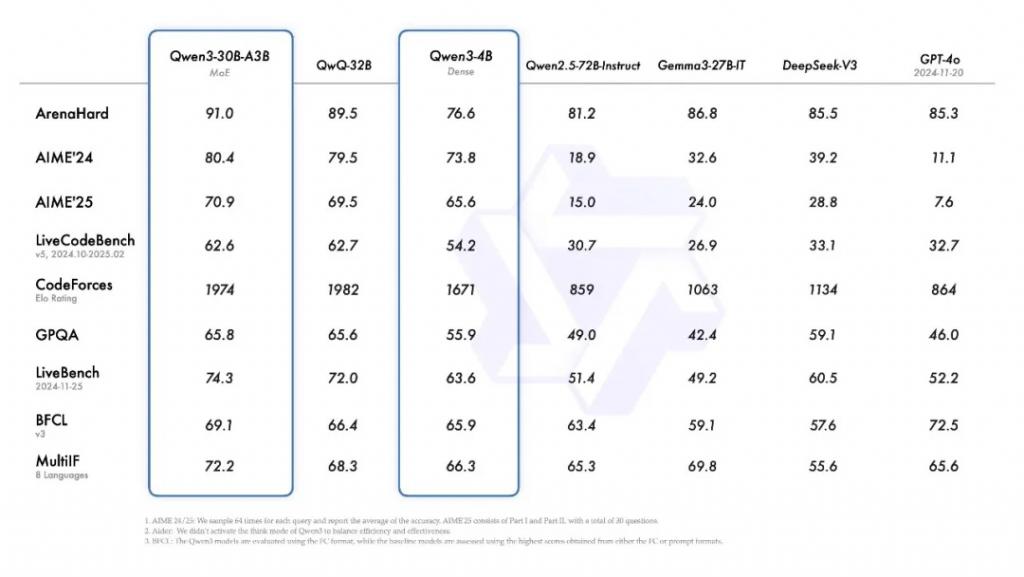
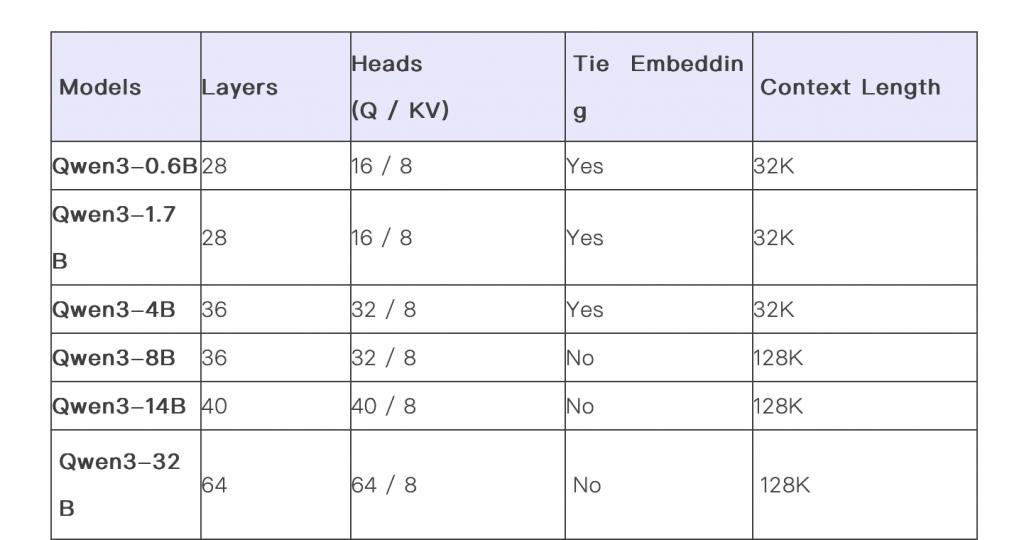
同时,阿里巴巴还开源了两个 MoE 模型的权重:拥有 2350 多亿总参数和 220 多亿激活参数的 Qwen3-235B-A22B,以及拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型 Qwen3-30B-A3B。此外,六个 Dense 模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。
" 混合型 " 模型,两种思考模式
阿里巴巴表示,Qwen 3 系列是 " 混合型 " 模型,既可以花时间 " 推理 " 以解决复杂问题,也可以快速回答简单请求,分别叫做 " 思考模式 " 和 " 非思考模式 "。" 思考模式 " 中的推理能力使得模型能够有效地进行自我事实核查,类似于 OpenAI 的 o3 模型,但代价是推理过程中的延迟时间较高。
Qwen 团队在博客文章中写道:
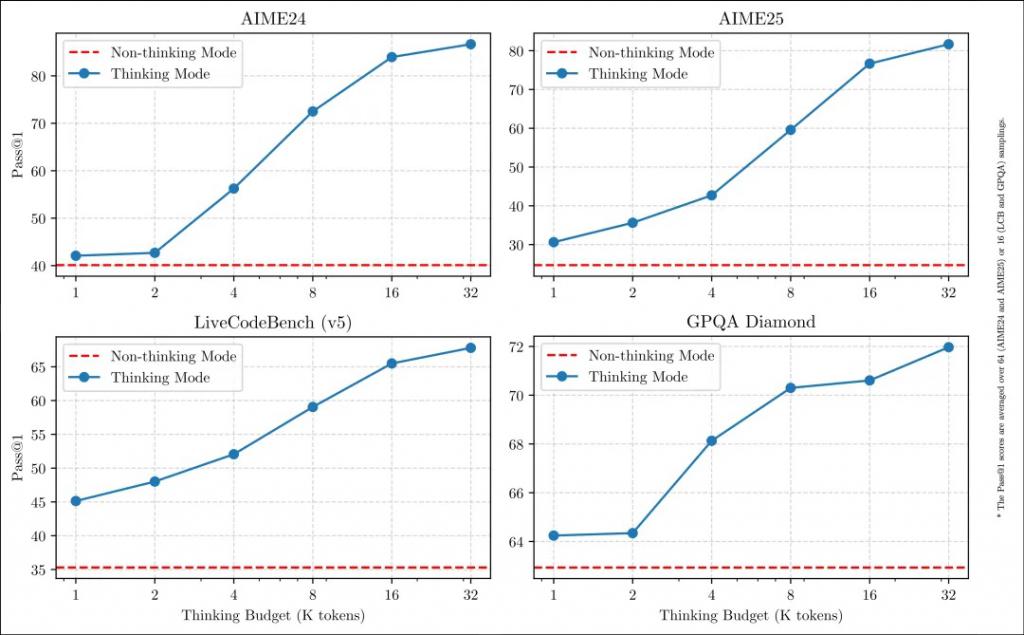
这种灵活性使用户能够根据具体任务控制模型进行 " 思考 " 的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。
至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的 " 思考预算 " 控制能力。如上文所述,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。
这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
训练数据量是 Qwen2.5 的两倍,便于 Agent 调用
阿里巴巴表示,Qwen3 系列支持 119 种语言,并基于近 36 万亿个 token(标记)进行训练,使用的数据量是 Qwen2.5 的两倍。Token 是模型处理的基本数据单元,约 100 万个 token 相当于 75 万英文单词。阿里巴巴称,Qwen3 的训练数据包括教材、问答对、代码片段等多种内容。
据介绍,Qwen3 预训练过程分为三个阶段。在第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。
在第二阶段(S2),训练则通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。在最后阶段则使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
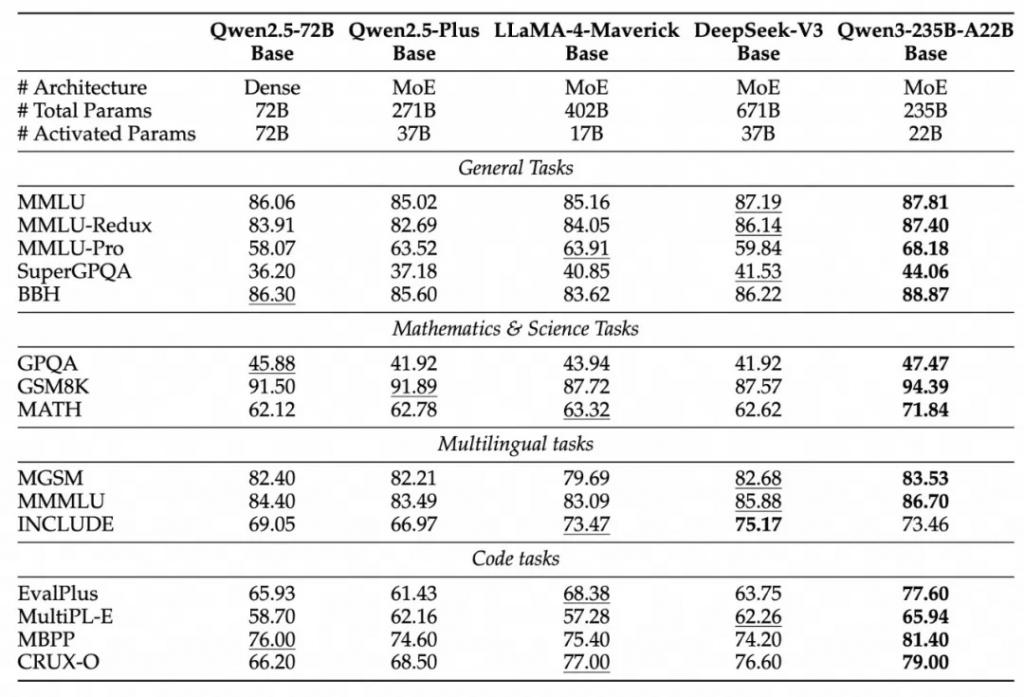
阿里巴巴表示,由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的 Qwen2.5 基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。对于 Qwen3 MoE 基础模型,它们在仅使用 10% 激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能,显著节省了训练和推理成本。
而在后训练阶段,阿里使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域,为模型配备基本的推理能力。然后通过大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
阿里巴巴表示,Qwen3 在调用工具(tool-calling)、执行指令以及复制特定数据格式等能力方面表现出色,推荐用户使用 Qwen-Agent 来充分发挥 Qwen3 的 Agent 能力。Qwen-Agent 内部封装了工具调用模板和工具调用解析器,大大降低了代码复杂性。
除了提供下载版本外,Qwen3 还可以通过 Fireworks AI、Hyperbolic 等云服务提供商使用。
目标仍对准 AGI
OpenAI、谷歌和 Anthropic 近期也陆续推出了多款新模型。OpenAI 近日表示,也计划在未来几个月发布一款更加 " 开放 " 的模型,模仿人类推理方式,这标志着其策略出现转变,此前 DeepSeek 和阿里巴巴已经率先推出了开源 AI 系统。
目前,阿里巴巴正以 Qwen 为核心,构建其 AI 版图。今年 2 月,首席执行官吴泳铭表示,公司目前的 " 首要目标 " 是实现通用人工智能(AGI)——即打造具备人类智力水平的 AI 系统。
阿里表示,Qwen3 代表了该公司在通往通用人工智能(AGI)和超级人工智能(ASI)旅程中的一个重要里程碑。展望未来,阿里计划从多个维度提升模型,包括优化模型架构和训练方法,以实现几个关键目标:扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围,并利用环境反馈推进强化学习以进行长周期推理。
开源社区振奋
阿里 Qwen3 的发布让 AI 社区感到激动,有网友献上经典 Meme:

有网友说,
在我的测试中,235B 在高维张量运算方面的表现相当于 Sonnet。
这是一个非常出色的模型,
感谢你们。
有网友对 Qwen3 赞不绝口:
如果不是亲眼看到屏幕上实时生成的 tokens,我根本不会相信那些基准测试结果。???? 简直像魔法一样 ????

而开源 AI 的支持者则更加兴奋。有网友说:
" 有了一个开源 32B 大模型,性能跟 Gemini 2.5 Pro 不相上下。"
" 我们彻底杀回来了!"

网友感谢阿里积极推动开源:
