OpenAI姚顺雨:大模型下半场是产品的游戏,做研究也要有产品思维
AI 趋势正在 " 中场休息 ",在此之前训练>评估,在此之后评估>训练。
这是OpenAI 员工、姚班校友姚顺雨给出的最新判断。
AI 发展分为上下两阶段。上半场以模型和方法为中心,核心构建了模型和训练方法;随着 AI 技术成熟,下半场的重点转向如何定义有现实意义的任务、如何有效评估 AI 系统的表现。
这要求研究者要及时转变思维和技能树方向,可能要更接近于产品经理。
为啥会出现这种转变?
因为强化学习终于能泛化了。
在姚顺雨最新的 blog 中,他系统性阐释了如上观点以及背后思考。想法刚刚发布就得到了不少业内人士的认可:
我同意你的观点。评估中还有一点值得考虑:成本成为越来越重要的影响因素。
离线 RL/ 无监督学习→在线 RL 学习策略。我们是不是已经准备好转型了?
值得一提的是,这篇文章也有 AI 参与了撰写。
这篇博文是基于我在斯坦福大学和哥伦比亚大学的演讲。我使用 OpenAI 深度研究来阅读我的 PPT 并打了草稿。
AI 下半场是产品的游戏
姚顺雨表示,人工智能发展走向新阶段,我们的思维方式应该变一变了。
把重点从解决问题转移到定义问题,在新时代评估比训练更重要。
我们不仅要思考 " 我们能否训练一个模型来解决 XX",而是要思考 " 我们应该训练 AI 做什么?我们如何衡量真正的进步?"
为啥这么说?
先来看 AI 的上半场发生了什么。
AI 上半场:方法为王
在 AI 发展的 " 前半场 ",最有影响力的工作主要集中在模型和训练方法(如 Transformer、AlexNet、GPT-3),而不是任务或基准。即便是非常重要的基准数据集如 ImageNet,其引用量也不到 AlexNet 的三分之一。

究其原因,是因为方法比任务更难、更有趣。
构建新算法或模型架构通常需要深刻的洞察和复杂的工程实践——比如反向传播算法、AlexNet、Transformer 这样的突破;相比之下,任务的设定往往只是把人类的已有任务(如翻译、图像识别)转化为可度量的标准,技术含量相对较低。
没什么洞察力,甚至都没什么工程力的体现。

加之,任务容易定义但不够通用,而方法(如 Transformer)却可被广泛应用到 NLP、CV、RL 等多个领域,从而产生跨任务的通用价值。
一个好的模型架构或算法可以在多个基准上 " 爬山 "(hillclimb),因为它具有通用性和简洁性。这也是为什么 " 方法胜于任务 " 在这个阶段成为主导逻辑。
尽管这种以 " 方法创新 " 为主导的范式持续多年并催生了巨大突破,但这些方法的积累最终带来了范式转变的临界点——
这些基础能力的集成已经可以构建出" 可工作的 AI 任务解法配方(recipe)",也就意味着:我们终于可以认真考虑如何解决真实任务本身,而不仅仅是构建更强的模型。
强化学习里,算法是次要的
姚顺雨认为,配方有三要素组成:
大规模语言训练
计算与数据的规模化
推理与行动
具备这三要素即可产出稳定且强大的 AI。
通过强化学习可以理解为何是这三要素。
强化学习的三大核心是算法、环境和先验知识。
长期以来,强化学习研究者大多主要关注算法,忽视环境和先验。但随着经验增长,大家发现环境和先验对实际效果影响巨大。

但是在深度强化学习时代,环境变得很重要。
算法的性能通常特定于它的开发和测试环境。如果忽视了环境,就可能建立一个 " 最优 " 的算法,但这个算法只是在特定情况下很强。
那为什么不首先找出真正想要解决的环境,然后再找最合适它的算法?
姚顺雨表示,这正是 OpenAI 最初的思路。
OpenAI 最初的计划就是把整个数字世界变成一个可以用强化学习解决的 " 环境 ",然后用聪明的 RL 算法来解决这些环境中的任务,最终实现数字通用人工智能(digital AGI)。
OpenAI 在这个思路下完成了很多经典工作,比如用 RL 打 Dota、解决机械手等。
但它并没有实现让 RL 解决计算机 / 上网的问题,RL Agent 也无法迁移到其他环境,似乎差了点什么。
到了 GPT-2/3 时期,OpenAI 意识到,缺的是先验知识。
需要引入强大的语言先验知识,才能解决在复杂环境中难以泛化的问题。这使得 RL Agent 在聊天或网页任务中有显著提升,如 WebGPT、ChatGPT。
但这好像和人类智慧上仍旧有差别,比如人类可以轻松上手一个新游戏、哪怕是零样本,但是当时 AI 做不到。
影响泛化的关键是 " 推理能力 "。
人类不是单纯执行指令,而是会进行抽象思考。比如:" 地牢危险 → 我需要武器 → 没有武器 → 可能藏在箱子里 → 箱子 3 在柜子 2 → 那我先去柜子 2"。
姚顺雨说,推理是种 " 奇怪 " 的动作。
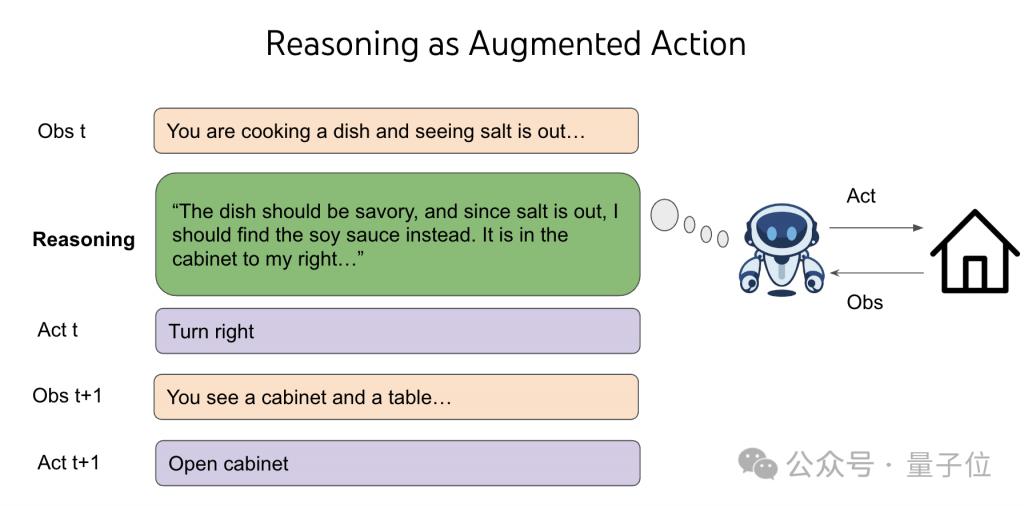
推理本身不直接改变世界,但其空间是无限组合的。在传统 RL 框架中,它是 " 不划算 " 的 —— 推理不像行动那样有即时反馈,反而会 " 稀释 " 奖励。
但如果把 " 推理 " 加入 RL 的动作空间,并结合语言预训练模型的先验,就可以带来极强的泛化能力。类似于:虽然你面对的是无限个空盒子,但你从过往经验中学会了如何在空盒子中识别有价值的选择。
所以,一旦有了好的语言预训练先验 + 合适的环境设计(允许语言推理),RL 法本身反倒变得次要。
o 系列、R1、Deep Research、智能体等,都是由此而来。
或许正如乔布斯所说,你无法预见未来的点点滴滴是如何连接的;只有回头看时,你才能把它们串联起来。
下半场要有新的评估规则
由此,配方改变了 AI 社区的比赛规则。
开发新模型→刷新基准→创建更难的基准→更强的新模型。
这种规则在 AI 发展的上半场是有必要的,因为在模型智能水平不够高时,提高智商通常会提高效用。
可问题是,尽管 AI 已经在各类基准测试(如围棋、SAT、律师考试、IOI 等)中超越人类,但这些成就并未真正转化为现实世界的价值或效用。
Jason Wei 的一张图可以很好解释这一趋势,AI 刷榜的速度越来越快,但是世界因此改变了吗?
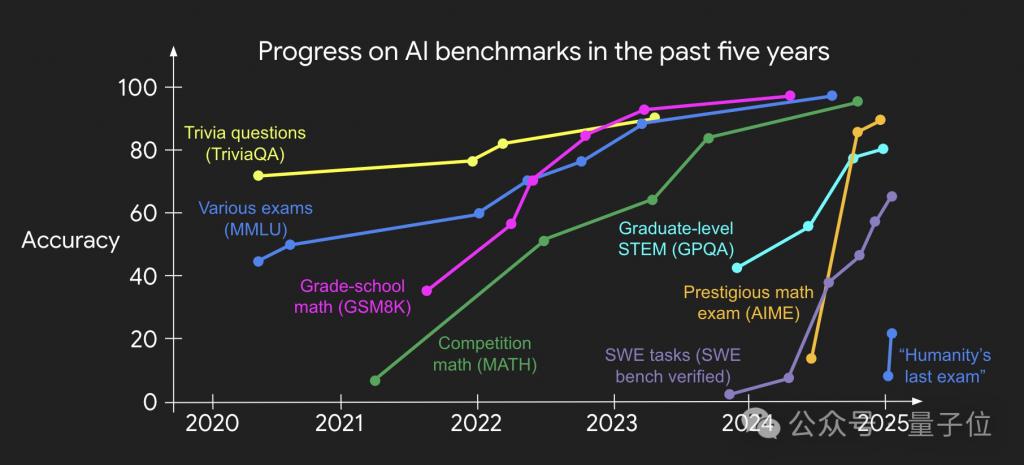
姚顺雨认为当前的评估方式主要存在两方面局限,导致 AI 在解决现实问题上严重脱节。
1、假设任务是独立同分布的(i.i.d.):
模型被要求独立完成每个任务,然后取平均得分。这种方式忽略了任务之间的连贯性和学习效应,无法评估模型长期适应能力和记忆机制的重要性。
2、假设评估过程应自动化且与人无关:
当前模型接收输入 → 完成任务 → 接收评分。但真实世界中,大多数任务(如客户服务、软件开发)都需要持续的人机互动。

解决之道就是重新设计评估方式,为下半场制定新的游戏规则。
姚顺雨认为创新的评估应该贴近现实世界任务、优化模型配方解决任务,形成新的正向循环。
这个游戏很难,因为它陌生,但是也很令人兴奋。
上半场的玩家解决视频、游戏和考试任务,下半场的玩家则利用智能创建有用的产品,建立起价值数十亿甚至数万亿美元的公司。
欢迎来到 AI 下半场!
姚班学霸、思维树作者
最后再来介绍一下本文作者姚顺雨。
他去年加入 OpenAI,担任研究员,负责研究智能体。
他身上的关键字有:
清华姚班
姚班联席会主席
清华大学学生说唱社联合创始人
普林斯顿计算机博士
他的研究成果包括:
思维树(Tree of Thoughts):让 LLM 反复思考,大幅提高推理能力。
SWE-bench:一个大模型能力评估数据集。
SWE-agent:一个开源 AI 程序员。

最后,想要阅读更原汁原味的版本,可戳:
https://ysymyth.github.io/The-Second-Half/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
不到一周!中国 AIGC 产业峰会观众正在火热报名中 ♀️
全部嘉宾已就位 百度、华为、AWS、MSRA、无问芯穹、数势科技、面壁智能、生数科技等十数位 AI 领域创变者将齐聚峰会,让更多人用上 AI、用好 AI,与 AI 一同加速成长~
4 月 16 日周三,就在北京,一起来深度求索 AI 怎么用
一键星标
科技前沿进展每日见